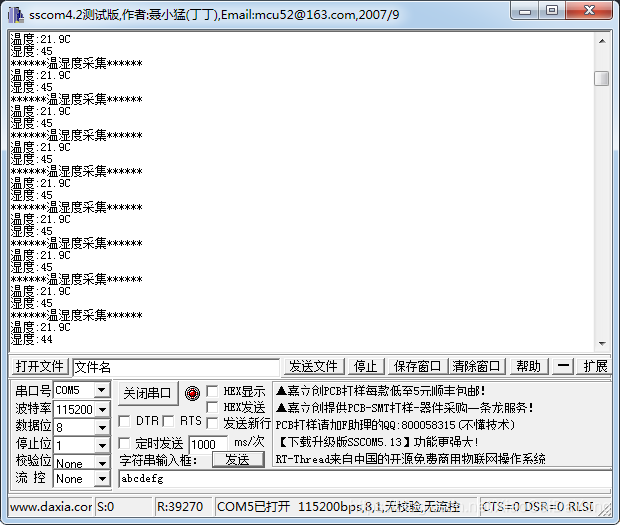
本文共 3928 字,大约阅读时间需要 13 分钟。
先看一下DHT11温湿度长的样子。
DHT11 是广州奥松有限公司生产的一款湿温度一体化的数字传感器。该传感器包括一个电阻式测湿元件和一个 NTC 测温元件,并与一个高性能 8 位单片机相连接。通过单片机等微处理器简单的电路连接就能够实时的采集本地湿度和温度。 DHT11 与单片机之间能采用简单的单总线进行通信,仅仅需要一个I/O 口。传感器内部湿度和温度数据 40Bit 的数据一次性传给单片机,数据采用校验和方式进行校验,有效的保证数据传输的准确性。 DHT11 功耗很低, 5V 电源电压下,工作平均最大电流 0.5mA。
工作电压范围:3.3V-5.5V
工作电流 :平均0.5mA
输出:单总线数字信号
测量范围:湿度20~90%RH,温度0~50℃
精度 :湿度±5%,温度±2℃
分辨率 :湿度1%,温度1℃
DHT11数字湿温度传感器采用单总线数据格式。单个数据引脚端口完成输入输出双向传输。
其数据包由5Byte(40Bit)组成。数据分小数部分和整数部分,一次完整的数据传输为40bit,高位先出。
DHT11的数据格式为:8bit湿度整数数据+8bit湿度小数数据+8bit温度整数数据+8bit温度小数数据+8bit校验和。
其中校验和数据为前四个字节相加。 传感器数据输出的是未编码的二进制数据。数据(湿度、温度、整数、小数)之间应该分开处理。
传感器数据输出的是未编码的二进制数据。数据(湿度、温度、整数、小数)之间应该分开处理。
DHT11 开始发送数据流程

主机发送开始信号后,延时等待 20us-40us 后读取 DH11T 的回应信号,读取总线为低电平,说明 DHT11 发送响应信号, DHT11 发送响应信号后,再把总线拉高,准备发送数据,每一 bit 数据都以低电平开始,格式见下面图示。如果读取响应信号为高电平,则 DHT11 没有响应,请检查线路是否连接正常。

首先主机发送开始信号,即:拉低数据线,保持t1(至少18ms)时间,然后拉高数据线t2(20~40us)时间,然后读取DHT11的响应,正常的话,DHT11会拉低数据线,保持t3(40~50us)时间,作为响应信号,然后DHT11拉高数据线,保t4(40~50us)时间后,开始输出数据。
主机复位信号和 DHT11 响应信号

数字‘ 0’信号表示方法
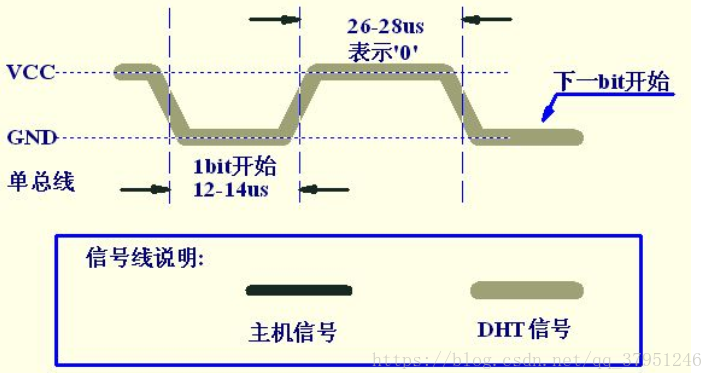
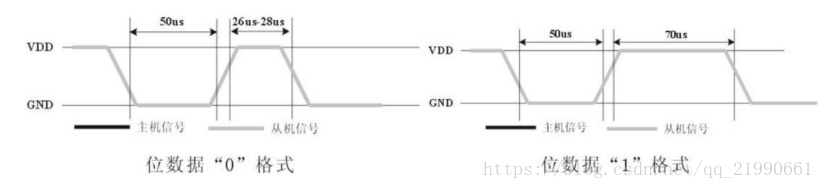
程序要区分数据0和数据1的格式:先判断此时引脚的电平状态,如果是低电平就一直循环等待,直到高电平出现,高电平出现后延时40us,并读取延时后的电平状态,如果此时是高电平,则数据为1,否则为0
传输完40位数据后,传感器再次输出一个50us的低电平后,将数据总线释放,采集过程结束。
代码如下:
选用的单片机型号:STM32L052K8* 其实哪个单片机无所谓的,主要是温湿度模块的实现
接线:PA6接在模块的DATA口上
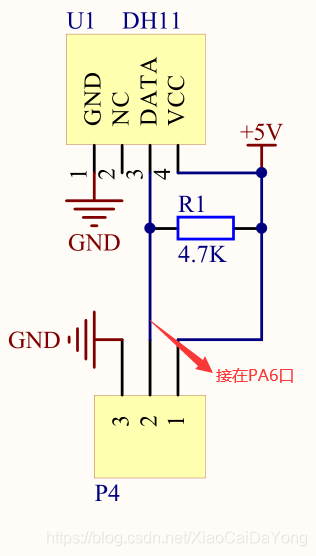
代码如下:
DHT11.c
#include "dht11.h"static GPIO_InitTypeDef GPIO_InitStruct;uint8_t U8FLAG,k;uint8_t U8count,U8temp;uint8_t U8T_data_H,U8T_data_L,U8RH_data_H,U8RH_data_L,U8checkdata;uint8_t U8T_data_H_temp,U8T_data_L_temp,U8RH_data_H_temp,U8RH_data_L_temp,U8checkdata_temp;uint8_t U8comdata;void delay_us(uint16_t j) //微秒延时 { uint8_t i; for(;j>0;j--) { for(i=0;i<8;i++); }}void delay_ms(uint16_t j) //毫秒延时 { uint16_t i; for(;j>0;j--) { for(i=0;i<8000;i++); }}void DHT11_INIT(void) //配置端口PA6{ __HAL_RCC_GPIOB_CLK_ENABLE(); GPIO_InitStruct.Pin = DHT11_SDA; GPIO_InitStruct.Mode = GPIO_MODE_OUTPUT_OD; GPIO_InitStruct.Pull = GPIO_NOPULL; GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH ; HAL_GPIO_Init(DHT11_COM, &GPIO_InitStruct); }void COM(void) //启动 读取{ uint8_t i; for(i=0;i<8;i++) { U8FLAG=2; //初始化数 while((!DHT11_SDA_READ())&&U8FLAG++); //读端口采集,低电平表示起始信号 delay_us(10); delay_us(10); delay_us(10); //等待 U8temp=0; if(DHT11_SDA_READ())U8temp=1; //有数据来 U8FLAG=2; while((DHT11_SDA_READ())&&U8FLAG++); //读取 if(U8FLAG==1)break; U8comdata<<=1; U8comdata|=U8temp; }}void RH(void) //{ DHT11_SDA_L(); //拉低 delay_ms(18); DHT11_SDA_H(); //拉高 delay_us(10); delay_us(10); delay_us(10); delay_us(10); //等待 if(!DHT11_SDA_READ()) //低电平进入 { U8FLAG=2; while((!DHT11_SDA_READ())&&U8FLAG++);//数据等待 U8FLAG=2; while((DHT11_SDA_READ())&&U8FLAG++); //启动 COM(); // U8RH_data_H_temp=U8comdata; //读取湿度高位 COM(); U8RH_data_L_temp=U8comdata; //读取湿度低位 COM(); U8T_data_H_temp=U8comdata; //读取温度高位 COM(); U8T_data_L_temp=U8comdata; //读取温度低位 COM(); U8checkdata_temp=U8comdata; //校验位 DHT11_SDA_H(); U8temp=(U8T_data_H_temp+U8T_data_L_temp+U8RH_data_H_temp+U8RH_data_L_temp);//40位数据相加 if(U8temp==U8checkdata_temp) //数据校验 对比 { U8RH_data_H=U8RH_data_H_temp; //把读取值付出 U8RH_data_L=U8RH_data_L_temp; U8T_data_H=U8T_data_H_temp; U8T_data_L=U8T_data_L_temp; U8checkdata=U8checkdata_temp; } }} DHT11.h
#ifndef __DHT11_H#define __DHT11_H/* Includes ------------------------------------------------------------------*/#include "stm32l0xx_hal.h"#define Data_0_time 4#define DHT11_SDA GPIO_PIN_6#define DHT11_COM GPIOA#define DHT11_SDA_H() HAL_GPIO_WritePin(DHT11_COM,DHT11_SDA,GPIO_PIN_SET)#define DHT11_SDA_L() HAL_GPIO_WritePin(DHT11_COM,DHT11_SDA,GPIO_PIN_RESET)#define DHT11_SDA_READ() HAL_GPIO_ReadPin(DHT11_COM,DHT11_SDA) //宏定义读数据extern uint8_t U8T_data_H,U8T_data_L,U8RH_data_H,U8RH_data_L,U8checkdata;void delay_us(uint16_t j);void delay_ms(uint16_t j);void DHT11_INIT(void);void COM(void);void RH(void);#endif /* __DHT11_H *//************************ (C) COPYRIGHT STMicroelectronics *****END OF FILE****/我的实现是通过串口实现的,串口的配置信息其实也很简单,这里就没有把串口的代码信息贴出,实现的效果如下: